
How ConsenseKit became RefactorKit
The more that I think about it, the more I believe that I’ve made a mistake in the product definition process for ConsenseKit. The practice of JTBD and ODI teaches that everything stems from the Core job to be done. It is a foundational concept that forms the basis for the job map, desired outcomes and more. Here’s what I learned, and why ConsenseKit is now RefactorKit.
With ConsenseKit, the core job is, for software decision makers to:
build consensus for hard tech decisions.
But this is only part of a larger job: actually making the decision. In general, a tech refactor is a more relatable and specific job that developers perform. Also, building consensus is only sometimes applicable, as some developers can make tech decisions without first needing consensus.
The new core JTBD is, for software developers to:
make large refactoring decisions consistently better
Fundamentally, this describes a different product. This is a fast pivot, and the only thing I spent was $12 for the ConsenseKit.com domain. Not bad, and shows how efficient ODI and JTBD can be. In return, the product is positioned more strategically towards a specific and well-researched problem set.
Introducing RefactorKit
The concept behind RefactorKit is much the same as ConsenseKit. However, the product specifically focuses on improving refactoring decisions. Building consensus is still sometimes part of the job, so perhaps they are “related jobs”, which is a term used in JTBD theory.
What is interesting is that when viewing the problem in terms of refactoring, there already exists a body of literature. Lepännen et al (2015) compared the refactoring process of 3 different software development companies using a task-based analysis. They were expecting to find similiar enough processes to be able to derive an abstract framework for making a refactoring decision. They were right, and based on my 10 years+ working on software, their framework for making refactoring decisions makes sense.
The Stages of Refactoring
What I understood was that the refactoring decision can be simplified to a sort of finite state machine. The codebase exists in a distinct state at any given time, and transitions to another state based on the presence of triggers and actions.
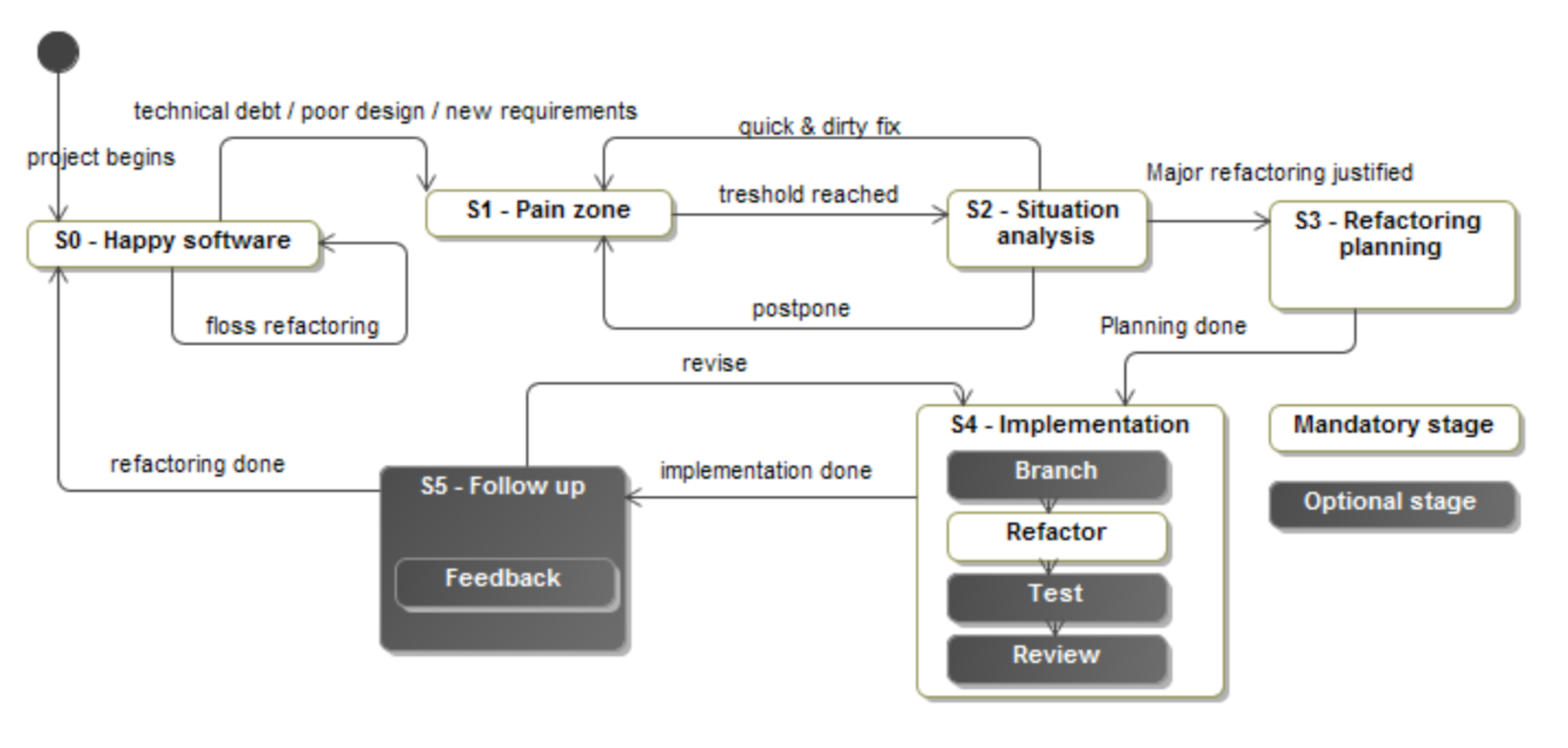
These are the states:
- Happy - No refactoring needed
- Pain zone - Flaws in code design are revealed, code smells accumulate, development velocity is observably slower. These are all some form of irritations to the developer, or business risk for management.
- Situation analysis - Once this “pain” reaches some threshold, the codebase enters into a state of review once the pain is communicated. The codebase is perceived as needing refactoring. Stakeholders (optionally devs/product/customer) come together to analyze benefits, alternatives, and ultimately make one of these decisions:
- Do nothing - continue in the pain zone for now
- Quick & dirty fix - continue with a hack that potentially makes pain zone worse
- Refactor - decision to justifiably modify codebase for future gains
- Refactoring planning - answers what, when and how to refactor
- Implementation - doing the refactor
- Follow-up (optional) - analysing the refactor for feedback, observable metrics
In terms of the Core JTBD, RefactorKit is concerned with helping software developers with all of these stages.
Research Analysis
- Refactoring decisions were observed to be made right after customer feature requests, or when developers instinctively decided that
"future development would be more difficult without refactoring". "A decision was made—often without much supporting empirical evidence beyond the intuition of a developer—to refactor code, trying to improve its qualities". This was a common theme in the study, with the results showing"...the initial idea of the need to refactor is rather subjective and not necessarily rational.", and"...the decisions are not based on metrics, but on a gut feeling.""The follow up (stage) is often omitted altogether. There is no clear process based on metrics how to decide, which refactoring case is the most important one.""The lack of metrics does not only exist in the situation planning and analysis stage, but also in stages before and after the refactoring decision.". This lack of metrics before the refactoring decision leads to"Software development teams were not necessarily able to foresee possible refactoring cases coming in the future".
Metric Analysis
We suspect that there do exist metrics that would allow development teams to analyze a refactoring decision better. These are discussed anecdotally by bloggers, and include:
- Feature delivery velocity
- Feature delivery throughput
- Defect (bugs) throughput
- Risk of missed deadlines or launch delays
- Time to onboard new employees
- Risk of cost overruns
There is a difficulty in terms of capturing these metrics, as they would need to be self-reported or integrated directly within an internal workflow management tool. Developers today are the key stakeholders which determine code smells and produce “pain zone” signals. At least by them knowing what the metrics ideally should consider, they can incorporate that into their judgement frameworks.
Limitations
While the decision making framework by Lepännen et al (2015) is useful for describing the refactoring process, the reality is that a codebase is not homogenous: some parts might be bad, some parts might be good. So a single codebase might exist in more than one finite state. The study also used subjective data from 3 companies in a single country.
References
Leppänen, Marko & Lahtinen, Samuel & Kuusinen, Kati & Makinen, Simo & Männistö, Tomi & Itkonen, Juha & Yli-Huumo, Jesse & Lehtonen, Timo. (2015). Decision-Making Framework for Refactoring. 10.1109/MTD.2015.7332627.

